Das sieht echt krass aus Ray. Gibt’s denn einen Punkt wo du sagst, man könnte mit starten sowas zu lernen? Coding im generellen oder speziell was zum Einstieg? Das man nicht gleich sowas komplexes bauen kann ist klar, aber ich würd gern in das Thema einsteigen
Du musst nichts coden. Wirklich nicht. Recherche reicht. (Und das Wissen über RegEx, Strings abschneiden etc.)
Das ist gar nicht schwer, wenn man die Arbeitsweise des HA mal kapiert hat.
Ich würde anfangen, die Werte des Bitaxe auszulesen. Das ist wirklich einfach und erfordert ein paar Zeilen, die ich dir geben kann (bzw. habe ich ja schon fast alles irgendwo gepostet).
Wenn du diese Werte schonmal hast, kannst du die mit Grafana in 0.nix visualisieren.
Die etwas komplexeren Sachen - wie die Tabelle vernünftig aufzubauen und die
Miner Worker auszulesen kannst du dann später machen.
Die meiste Arbeit ist es, sich die ganzen Sachen auf Webseiten zusammensuchen und Werte richtig skalieren. Aber auch das hab ich irgendwo schon gepostet.
Und der ultimative Tipp: Sag einfach dem ChatGPT was du machen willst, der schreibt dir schon 80% der Config.
Sag ihm vorher, dass du die Skripte für den HA haben möchtest.
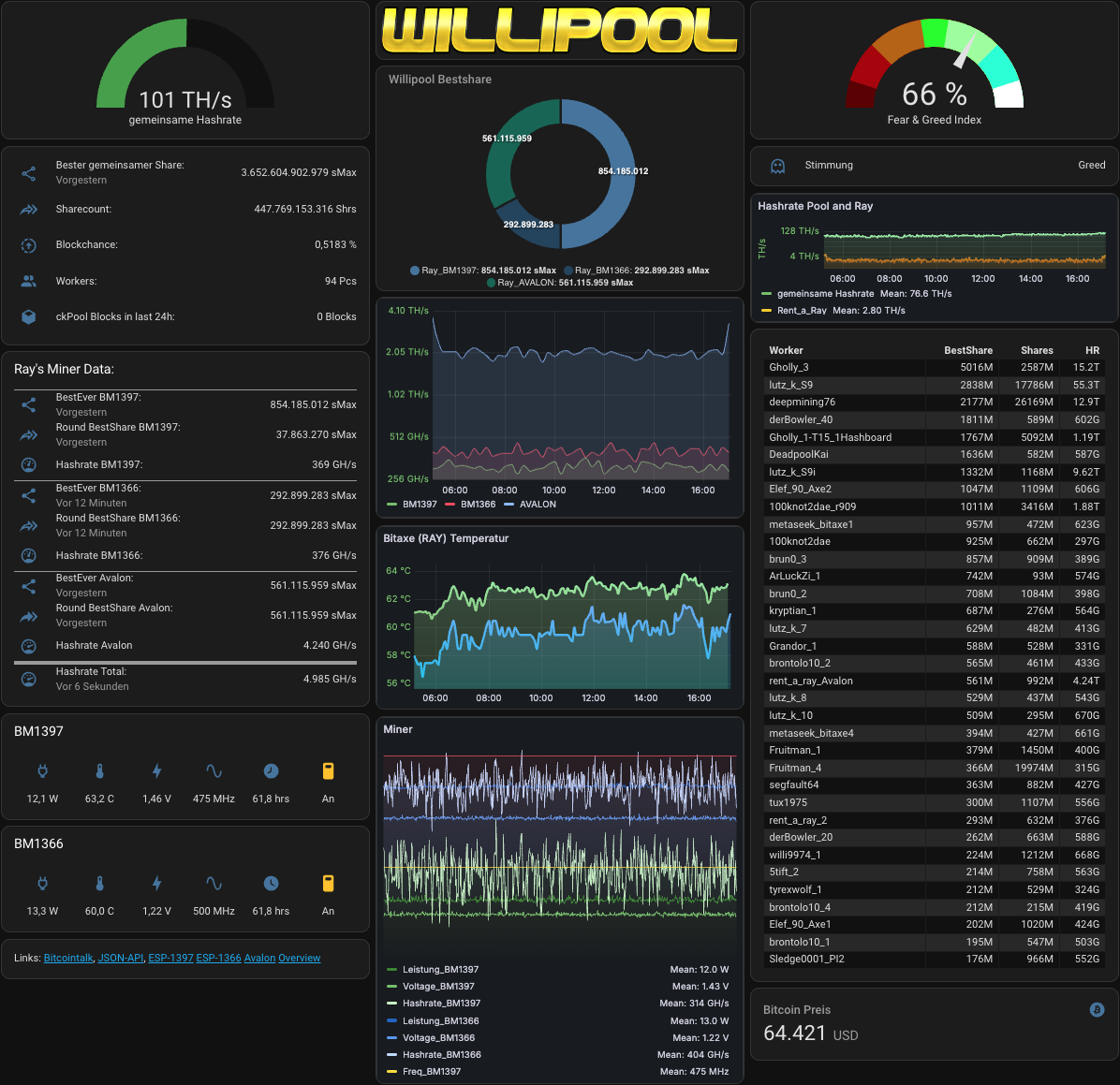
Übrigens, effizienter ist Willis Methode. Wenn ich wirklich alte History-Data einsehen will, muss ich das im Grafana-Plugin machen.
Das hier taugt nur zu einer groben Gesamt-Übersicht. Mehr Schein als sein und meine "BestShares" werden dadurch auch nicht besser.

Was mir aber mittlerweile (in meinem Setup) aufgefallen ist: Die instabilsten Miner (hohe Temperatur, viele abgelehnte Shares) machen die besten, frühen und höchsten Shares. Ich weiß wirklich nicht woran das liegt.
Der BM1937 ist sowas von kaputt, schlecht gekühlt (weil das ASIC-Innenleben an einer Ecke fast offen liegt, durch zu viel abschleifen etc), inkonsequent, braucht viele Neustarts und überrascht trotzdem immer wieder mit neuen, hohen Roundshares. Ob man das mal genauer untersuchen sollte?







 Hätten unseren Megarun jetzt starten müssen lol
Hätten unseren Megarun jetzt starten müssen lol